To expose a parameter for the model user:
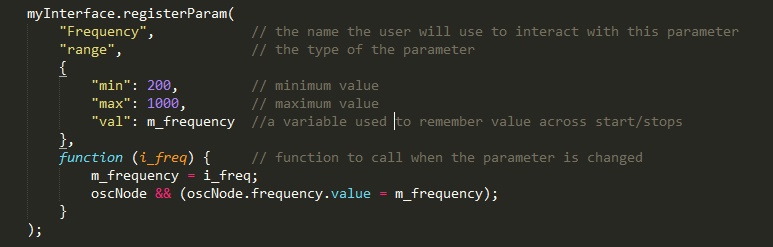
After that, model users can call the setParam and getParam family of methods in the jsaSound user interface.
jsaSndLib helps you do 2 things:
You will typically create your sound models by connecting audioNodes together just as your normally do when using the WebAudio API. Then use the jsaSound Library magic.
There is a "base sound model" function object that gives you:

One of the key features of jsaSound is the standardized interface it presents to the world.
To expose a parameter for the model user:
After that, model users can call the setParam and getParam family of methods in the jsaSound user interface.



